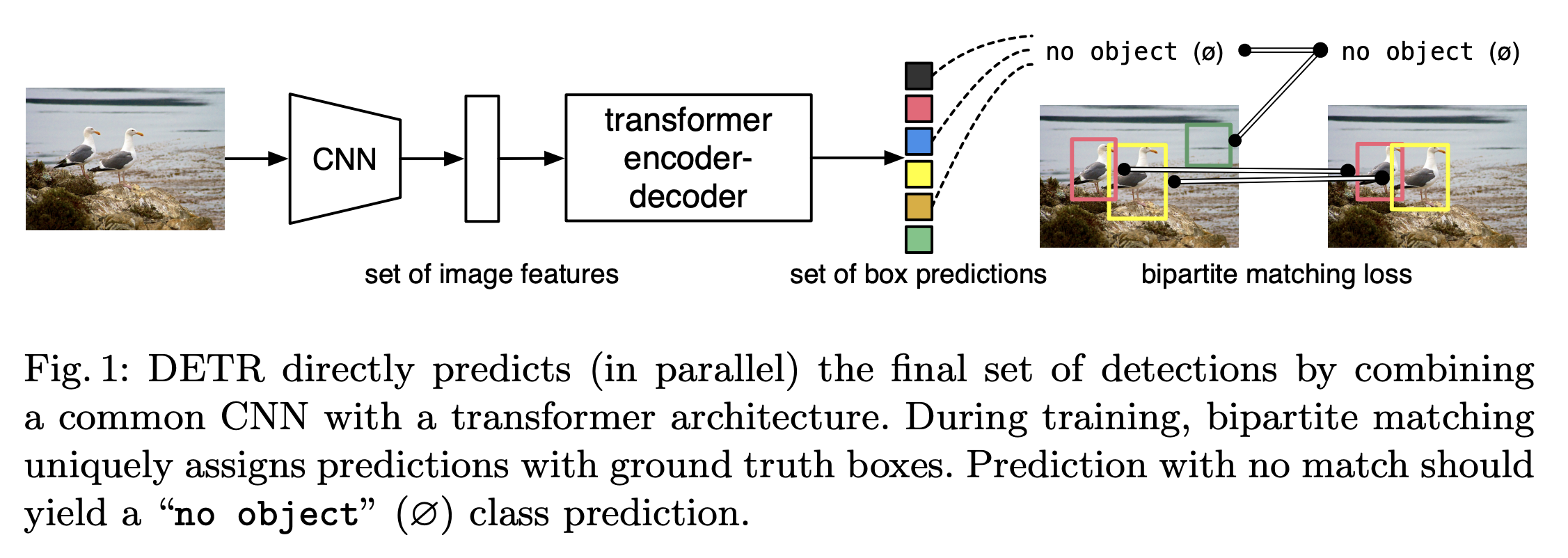
DETR
End-to-End Object Detection with Transformers[1]
作者们是来自Facebook AI的Nicolas Carion, Francisco Massa等。论文引用[1]:Carion, Nicolas et al. “End-to-End Object Detection with Transformers.” ArXiv abs/2005.12872 (2020): n. pag.
Key Words:
- a set of prediction loss(biparitte matching loss)
- Transformer with parallel encoding
总结
以下“我们” 指代作者
- 提出了一个新的方法:将目标检测看作是直接的集合预测问题(set prediction problem),精简了检测的pipeline,去掉了很多手工设计的组件,像是NMS非极大值抑制和anchor generation。新方法DEtection TRansformer (DETR)的主要的要素是 set-based global loss(通过两个部分的匹配(bipartite matching)强制唯一的预测)和transformer的encoder-decoder架构。给定一个固定的小的learned object queries的集合,DETR推理物体和global image context的关系,直接并行地输出最后预测的集合。在COCO目标检测数据集上,DETR展示了和Faster RCNN相当的精度和实时的性能。DETR能够很容易推广来产生全景的分割 in a unified manner。
Modern detector通过定义在a large set of proposals、anchors、windows centers的回归和分类来进行预测。这样做,性能会被以下因素影响:后处理的步骤(合并相似的预测)、anchor sets的设计和用于将目标框分配给anchors的启发式方法。
DETR没有很多手工设计的组件(which encoder prior knowledge, like spatial anchors or NMS),DETR不要求任何customized layers,能够在任何包含标准CNN和transformer classes的框架中复现。
DETR在大的目标的检测上性能很好,可能是由于transformer的non-local的计算。然而,在小目标上的检测性能就比较低,DETR能够容易地扩展到更复杂的任务
Transformers 引入了自注意力,类似于Non-Local Neural Networks。
Loss
find bipartite matching between GT and predictions, search for a permutation of N elements \(\sigma\) with the lowest cost:
\[\hat{\sigma}=\underset{\sigma\in\mathfrak{S}_N}{\operatorname*{\arg\min}}\sum_i^N\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})\]
\(\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})\) 是pairwise matching cost between GT \(y_i\) 和prediction \(\hat{y}_{\sigma(i)}\), 最优的assignment是通过匈牙利算法得到的。这个matching的作用和其它检测器中的match proposal or anchors一样。
Hungarian Loss: \[\mathcal{L}_\text{Hungarian}{ ( y , \hat { y })}=\sum_{i=1}^N\left[-\log\hat{p}_{\hat{\sigma}(i)}(c_i)+\mathbb{1}_{\{c_i\neq\varnothing\}}\mathcal{L}_{\mathrm{box}}(b_i,\hat{b}_{\hat{\sigma}}(i))\right]\]
\[Attention(Q,K,V)={softmax}(\frac{QK^T}{\sqrt{c}})V\ (Equation 3)\]
Architecture and Pipeline
- 输入图像 \(3 \times H_0\times W_0\) 进入CNN Backbone, 得到 \(C \times H \times W\) 维的activation map \(f\),\(C\)通常是2048。
- 通过 \(1 \times 1\) 卷积,将\(f\) 从 \(C\) 维降到 \(d\)维,得到 new feature map \(z_0,d \times H \times W\)。因为encoder是序列作为输入的,所以将 \(z_0\) 的空间维度合并,得到$d HW $的feature map。每个encoder layer包含多头注意力和 一个feed forward network (FFN),将positional encodings加入到每个注意力层。FFN 是一个3层的带有ReLU激活函数的感知机,FFN预测normalized 中心坐标、box相对于输入图像的高和宽,线性层用一个Softmax函数预测类标签。