VideoMAE
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pretraining[1]
作者是Zhan Tong, Yibing Song, Jue Wang 和王利民,分别来自南大,腾讯和上海AI Lab,论文引用[1]:Tong, Zhan et al. “VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training.” ArXiv abs/2203.12602 (2022): n. pag.
Time
Key Words
- video masked autoencoder using plain ViT backbones, tube masking with high ratio
- data-efficient learner that could be successfully trained with only 3.5k videos. Data quality more important than quantity for SSVP(self-supervised video pretraining) when a domain shift exists between source and target dataset.
动机
对于Video Transformers,通常是derived from 基于图像的transformer,严重依赖于从大规模图像数据的pre-trained models,高效地训练一个vanilla vision transformer on the video dataset without any pre-trianed model or extra image data是一个挑战。 ### 总结 以下“我们”指代作者
3个重要的VideoMAE的findings:
- 极高比例的掩码比率(masking ratio, 90%-95%)
- VideoMAE在非常小的数据集上实现了很好的效果
- VideoMAE展示了,对于视频自监督预训练,数据的质量比数据的数量更重要。
对于Video transformers, 它们通常是起源于image-based transformers,严重依赖于从大规模的图像数据中得到的预训练模型。 之前从0开始训练video transformers产生了并不满意的结果。因此 learned video transformers are biased by image-based dmodels。how to effectively and efficiently train a vanilla vision transformer on video dataset without using pre-trained model or extra data是一个挑战。自监督学习用大规模的图像数据展示出来亮眼的性能。
VideoMAE继承了简单的masking和reconstructing的pipeline,但是由于视频的额外的时间维度使得masking model与图像有所不同。
- 视频帧是densely captured,语义随时间变化缓慢,时间冗余会增加在有很少的高级理解的情况下,从时空邻域恢复missing pixels的风险。
- 视频可以看作是静态apprearance的时间进化,帧之间存在关联,这个时间联系在reconstruction中可能导致信息泄露。
由于时间冗余,采用极高的masking ratio,来drop cubes from downsampled clips;考虑到时间关联,想出了一个简单的tube masking strategy,事实证明这个在reconstructing中有助于降低信息泄露的风险。
Related Work
Video Representation Learning: 对比学习用来学习视觉表征很流行,然而这些方法严重依赖于strong 数据增强和large batch size。
BeiT, BEVT, VIMPAC followed BERT and 提出了从图像和视频通过预测离散的tokens学习视觉表征
Proposed Method
ImageMAE是 masking and reconstruction task with 非对称的encoder-decoder架构。
视频数据特征:temporal redundancy and temporal correlation。
VideoMAE:
- takes downsampled frames as inputs and uses cube embedding to obtain video tokens
- tube masking with high ratio to perform MAE pretrianing, backone is vanilla ViT with joint space-time attention
- 从原始视频V中随机采样得到包含t个连续帧的clip,然后用temporal samplign来压缩clip至T frames,stride 在Kinectics 和Something-Something数据集上分别取4和2。
- joint space-time cube embedding,每个cube的size是\(2 \times 16 \times 16\),能够降低输入的时空维度。
着重解释一下 Joint space-time Attention: 在ViViT那篇论文里,Spatio-temporal attention:simply forwards all spatio-temporal tokens extracted from the video, through the transformer encoder, each transformer layer models all pairwise interactions between all spatio-temporal tokens, 因此:Multi-Headed Self Attention has quadratic complexity with respect to the number of tokens.
VideoMAE-Action-Detection代码:
- 链接:
- https://github.com/MCG-NJU/VideoMAE-Action-Detection
- 数据处理:
- 数据集: ava.py里定义了class AVAVideoDataset,在training的时候,box_file = None,就是没有用到detected boxes,读取的标注文件是ava_train_v2.2_min.json, 就是ground truth。box也是来自于ava_train_v2.2_min.json;在validation的时候,只用detected box,ava_val_det_person_bbox.json
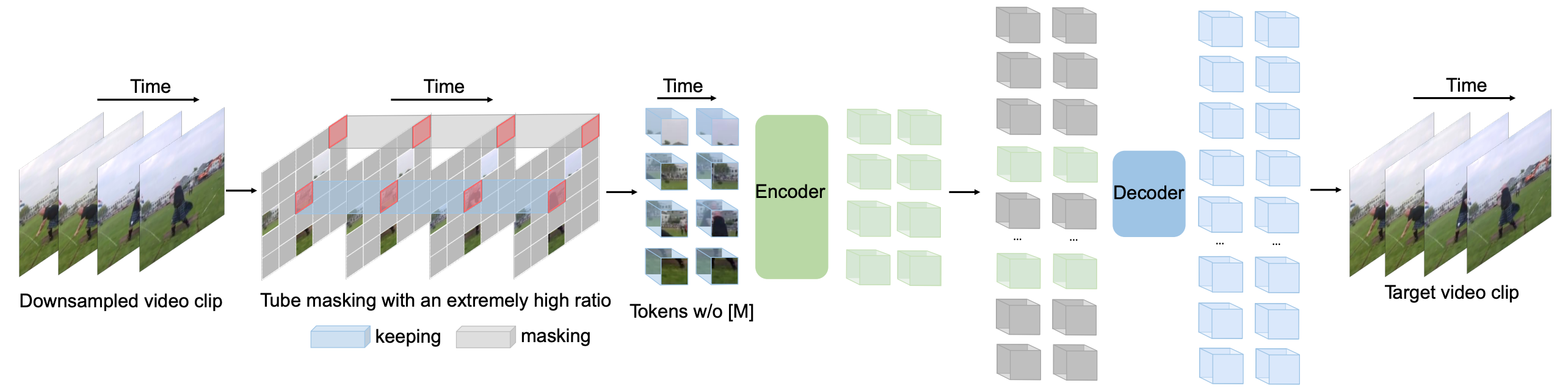 \(Figure\ 1^{[1]}\):
VideoMAE performs the task of masking random cubes and reconstructing
the missing ones with an asymmetric encoder-decoder architecture. Due to
high redundancy and temporal correlation in videos, we present the
customized design of tube masking with an extremely high ratio (90% to
95%). This simple design enables us to create a more challenging and
meaningful self-supervised task to make the learned representations
capture more useful spatiotemporal structures.
\(Figure\ 1^{[1]}\):
VideoMAE performs the task of masking random cubes and reconstructing
the missing ones with an asymmetric encoder-decoder architecture. Due to
high redundancy and temporal correlation in videos, we present the
customized design of tube masking with an extremely high ratio (90% to
95%). This simple design enables us to create a more challenging and
meaningful self-supervised task to make the learned representations
capture more useful spatiotemporal structures.