RCNN Series
RCNN[1]、Fast RCNN[2]、Faster RCNN[3] Mask RCNN[4]系列
- 目标检测的two-stage 方法的系列,从RCNN 到Faster RCNN,RCNN的作者是来自UC Berkeley的Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik;Fast RCNN的作者是来自Microsoft Research的Ross Girshick;Faster RCNN的作者是来自Microsoft Research的Shaoqing Ren, Kaiming He, Ross Girshick, 和孙剑; Mask RCNN的作者是论文引用[1]:Girshick, Ross B. et al. “Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation.” 2014 IEEE Conference on Computer Vision and Pattern Recognition (2013): 580-587. [2]:Girshick, Ross B.. “Fast R-CNN.” (2015).,[3]:>作者是来自Microsoft Research的Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun.[4]:
相关资源
这是一个openmmlab中算法的一些教程和学习资料,介绍的还不错
这个是百度PaddlePaddle的资料:
Time
- RCNN: 2013.Nov
- Fast RCNN: 2015.Apr
- Faster RCNN: 2015.Jun
RCNN
Key Words
- selective search
- region proposal总结:
- 包括三个模块: category-independent region proposals, defines the set of candidate detections available to detector; 第二个是 CNN网络,extracts a fixed-length feature vector from each region; 第三个是 a set of class-specific linear SVMs。
- 用Selective Search选出proposals,然后给到CNN,最后进行Softmax分类和bbox regression
- 缺点:
- 计算量太大,因为需要对每个proposal都做一次CNN, 训练时,需要对每个proposal都做一次CNN,然后做loss,这样很慢
- 为了计算features for a region proposal,需要将image data转换成特定的尺寸。用暴力的方式(warp and dilate)
 \(Fig. 1^{[1]}\): Object
detection system overview. Our system (1)takes an input image, (2)
extracts around 2000 bottom-up region proposals, (3) computes features
for each proposal using a large convolutional neural network (CNN), and
then (4)classifies each region using class-specific linear SVM
\(Fig. 1^{[1]}\): Object
detection system overview. Our system (1)takes an input image, (2)
extracts around 2000 bottom-up region proposals, (3) computes features
for each proposal using a large convolutional neural network (CNN), and
then (4)classifies each region using class-specific linear SVM
Fast RCNN
Key Words
- RoI pooling layer
总结
在feature map上做selective search,后面思路一样
思路:将整张图片和a set of object proposals作为输入,network first processes the whole image with several conv and max pooling lays to produces a conv feature map, 对于每个object proposal, RoI pooling Layer抽取 a fixed-length feature vector from the feature map, features are extracted for a proposal by max pooling the portion of the feature map inside the proposal into a fixed-size output. each feature vector is fed into a sequence of fully connected layers that finally branch into two sibling output layers:分类和回归。
 \(Fig.1^{[2]}\).
Fast R-CNN architecture. An input image and multiple regions of interest
(RoIs) are input into a fully convolutional network. Each RoI is pooled
into a fixed-size feature map and then mapped to a feature vector by
fully connected layers (FCs).The network has two output vectors per RoI:
softmax probabilities and per-class bounding-box regression offsets. The
architecture is trained end-to-end with a multi-task loss.
\(Fig.1^{[2]}\).
Fast R-CNN architecture. An input image and multiple regions of interest
(RoIs) are input into a fully convolutional network. Each RoI is pooled
into a fixed-size feature map and then mapped to a feature vector by
fully connected layers (FCs).The network has two output vectors per RoI:
softmax probabilities and per-class bounding-box regression offsets. The
architecture is trained end-to-end with a multi-task loss.
Faster RCNN
Key Words
- Region Proposal Network
- Translation-Invariant Anchors
总结
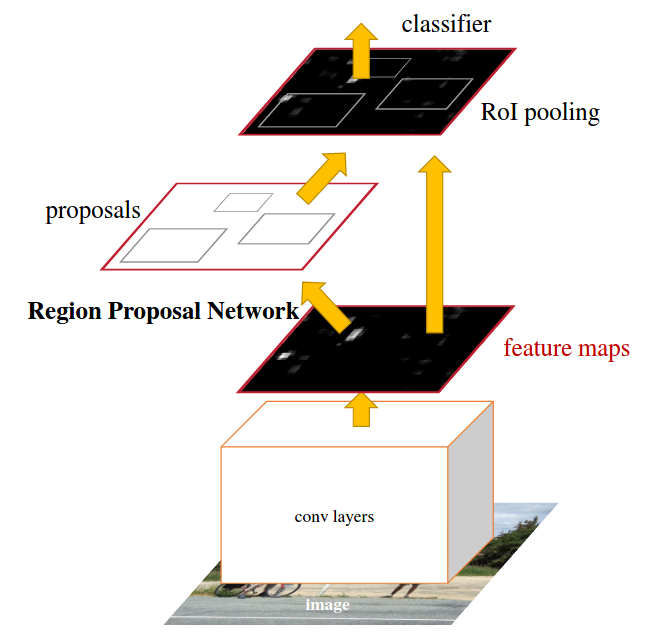
当前的目标检测算法依赖于region proposal 算法来假设object locations,像是SPPNet和Fast RCNN,已经减少了这些检测网络的运行时间,region proposal 的计算成为了一个瓶颈,在这篇工作中,引入RPN网络,shares full-image conv features with detection network,enabling nearly cost-free region proposals. RPN是一个全卷积的网络,simultaneously predicts object bounds and objectness scores at each position. RPN是能够端到端的训练来产生高质量的region proposals, which are used by Fast RCNN for detection. 然后将RPN和Fast RCNN融合进一个单个网络通过sharing conv features. RPN网络告诉unified network where to look。RPN通过加一个额外的conv layers,能够simultaneously regress region bounds and objectness scores at each location on a regular grid. RPN是一个全卷积网络(FCN)。
将Selective search这个步骤换成了一个Region Proposal Network(RPN),用RPN来代替Selective Search的功能,产生proposals,然后剩下的就是Fast RCNN部分。
不同于以往的pyramids of images/filters, 引入了anchor boxes, serve as references at multiple scales and apsect ratios. 作者们的方法可以被视为 a pyramid of regression references. 避免了枚举images or filters。训练的策略:alternates between fine-tuning for 目标检测 and fine-tuning for region proposal,while keeping proposals fixed.这个策略收敛很快。
广泛用的proposal methods有: Selective Search, EdgeBoxes...,这些object proposal methods是作为独立于检测器的模块。RCNN主要是作为一个分类器,不预测object bounds(except for refining by bounding box regression),之前的Multibox从网络中产生region proposals,它的最后的全连接层同时预测multiple class-agnostic boxes。用来预测bbox时,proposal和detection是不共享features。
RPN网络将任意尺寸的图片作为输入,输出一些矩形的object proposals,each with an objectness score。为了产生region proposals,在最后一个conv layer输出的feature map上slide a small network, 这个network将 输入的feature map的 \(n \times n\)的 spatial window作为输入,每个sliding window is mapped to 一个低维的feature,这个feature然后送到两个full-connected layers: box regression layer和box classification layer,
- Anchors: 在每个sliding-window的位置,同时预测多个region proposals,每个位置的最多可能的proposals是k个,所以regression layers有4k个输出(coordinates of k boxes),cls layer输出2k个scores(每个proposal,预测object的概率或者不是object的概率),Anchor是sliding window的中心,associated with a scale and aspect ratio. 默认是3个scales和3个aspect ratios,在每个sliding position产生9个anchors,对于尺寸为 $ W H $的feature map,总共有 \(WHk\)个anchors.
- Translation-Invariant Anchors: 该方法的一个重要的特点是translation invariant,both in terms of functions和anchors that computer proposals relative to anchors。如果object in an image 被translate,则proposal tranlate,同样的function能够去预测proposal。相比之下,Multibox没有这个特点,它用k-means来产生800个anchors,which are not translation invariant.
- Multi-Scale Anchors are Regression References: 作者的设计提出了一个新的方法来解决multiple scales的问题。有两种流行的方法for multi-scale predictions:一个是基于image/feature pyramids(DPM, CNN),图像被resized at multiple scales,每个scale都要计算feature map,这个通常耗时;第二个是用multiple scales的sliding windows on feature maps。作者的方法是基于pyramid of anchors,regress bbox with reference to anchors boxes of multiple scales and aspect ratios. 这个multi-scale anchors的设计是key component for 共享feautres without extra cost for addressing scales.
对于多种的size,a set of k 个regressors do not share weights. 即使features are of a fixed size/scale, 预测不同size的box是可能的。

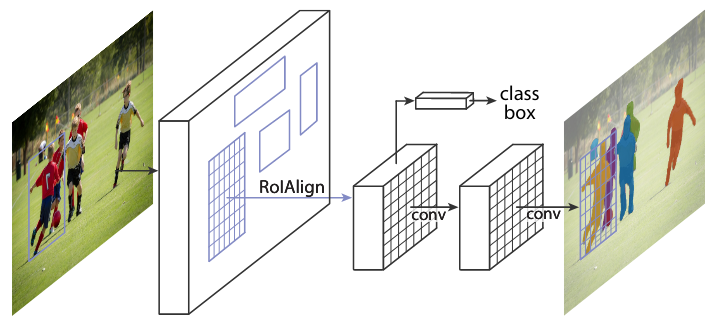
Mask R-CNN
- 将Faster RCNN中的RoI Pooling换成RoI Align,就是在Pool的时候,将一个很糙的划分变成一个精细的划分,能够实现像素的分类。