ViT
An Image is Worth \(16 \times 16\) Words:Transformers For Image Recognition at Scale[1]
作者比较多,都是来自Google Research, Brain Team的Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer,Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. 论文引用[1]:Dosovitskiy, Alexey et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ArXiv abs/2010.11929 (2020): n. pag.
Time
- 2020.Oct
Key Words
- Vision Transformer
- Image patches (in Vision) \(\Leftrightarrow\) tokens (words) in NLP
- larger scale training
总结
- 自注意力机制的dominant approach is 在large text corpus预训练,然后在smaller task-specific dataset上进行微调。Thanks to Transformers' computational efficiency 和可扩展性(scalability), 训练一个over 100B parameters、unprecedented size的model成为可能。随着model和dataset的growing,没有饱和的迹象(no sign of saturating performance)
当在mid-sized dataset上 without strong regularization训练时, model产生的modest accuracies of a few percentage points below ResNets of comparable size. Transformer 缺少 inductive biases,(inherent to CNNS),例如 translation equivariance and locality(局部性),因此在训练不足的数据时,泛化性不好。
当在更大的数据集上训练时(14M-300M images),大规模训练胜过了归纳偏置,(large scale training trumps inductive bias), 在足够规模的的数据上进行训练,然后用fewer datapoints迁移到任务时,取得了很好的效果。
自Transformer于2017年提出之后,有很人尝试将Transformer应用到Vision任务上,有的是将自注意力应用到局部邻域 for each query pixel instead of globally. 这样的局部多头自注意力 dot-product self-attention blocks能够完全替代卷积。还有人用Sparse Transformers employ scalable approximations to global self-attention. 另外一种scale attention的方式是 apply it in blocks of varying sizes。最相近的做法是从input image 里抽取出 \(2 \times 2\)的 patches。还有很多将self-attention和卷积结合起来的做法:e.g 用self-attention来处理CNN的输出。最近的一个模型是image GPT(iGPT),在减小image resolution和color space之后,将Transformer应用到 image pixels, 作为生成式模型,该模型是以无监督的方式进行训练的。
ViT:
- 标准的Transformer接受1D的 sequence of token embeddings, 为了处理2D image,将image \(X \in R^{H \times W \times C}\), reshape成 a sequence of flattened 2D patches \(X_p \in R^{N \times (P^2 * C)}\), \((H,W)\)是原始图片的resolution, \(C\)是 channel的数量,\((P,P)\)是 resolution of each image patch, \(N = HW/P^2\),N是 patch的数量,也是 effective input sequence length for the Transformer. Transformer在所有层中用一个常量\(D\),表示latent vector size。所以将flatten patches 然后map to D 维 with a trainable linear projection,将这个project的输出称为patch embeddings。
- 与BERT的 [class] token类似,prepend一个learnable embedding to the sequence of embeded patches(\(z^0 = X_{class}\)),其在Transformer encoder输出的state(\(z^0_L\))作为image representation y,在预训练的时候,分类头是一个隐藏层的MLP,在fine-tuning的时候,是单个linear layer.
- Position embedding也加入到patch embeddings 来保持位置信息。用一个标准的可学习的1D position embeddings,没有观察到用更高级的2D-aware position embeddings带来更好的效果。
- 用公式表示为:
\[\begin{gathered} \mathbf{z}_{0} =[\mathbf{x}_{\mathrm{class}}; \mathbf{x}_{p}^{1}\mathbf{E}; \mathbf{x}_{p}^{2}\mathbf{E};\cdots; \mathbf{x}_{p}^{N}\mathbf{E}]+\mathbf{E}_{pos} \\\mathbf{E}\in\mathbb{R}^{(P^{2}\cdot C)\times D}, \mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D} \left(1\right) \\ \mathbf{z}^{\prime} _\ell=\mathrm{MSA}(\mathrm{LN}(\mathbf{z}_{\ell-1}))+\mathbf{z}_{\ell-1}, \ell=1\ldots L \left(2\right) \\ \text{z} _{\ell}=\mathrm{MLP}(\mathrm{LN}(\mathbf{z}^{\prime}{}_{\ell}))+\mathbf{z}^{\prime}{}_{\ell}, \ell=1\ldots L \left(3\right) \\ \mathbf{y}=\mathrm{LN}(\mathbf{z}_{L}^{0}) \left(4\right) \end{gathered}\]
Inductive bias:ViT 有更少的image-specific 归纳偏置 than CNNs,在CNNs,locality, two-dim neighborhood structure and translation equivariance are baked into each layer throughout the whole model。在ViT中,只有MLP层是local 和translation equivariant,self-attention是global的。two-dim neighborhood structure用的很少:在模型的开始,将image 切成patches,在fine-tuning的时候调整position embeddings for images of different resolution。除此之外,position embeddings 在初始化的时候没有carry 关于patches的2D的位置信息,所有的spatial relations between patches 是学来的from scratch.
混合架构:就是从CNN feature map中得到patches, project to Transformer。
当feeding 高分辨率的图像时,保持patch size相同, results in a larger effective sequence length。 ViT能够处理任意的sequence length(取决于memory constraints),然而,pre-trained position embeddings可能不再有意义。因此执行2D interpolation(2D插值) of the pre-trained position embeddings,根据它们在原始图像中的位置。注意到:这个resolution 调整和patch extraction 是 only points at which 关于Image 的2D 结构的归纳偏置引入到ViT中。
评估ResNet, ViT和hybrid的representation learning:在不同的datasets上预训练,ViT以更低的pre-training cost(compoutiaional cost)得到了state-of-the-art。最后用self-supervised做了一个小实验,展示了self-supervised ViT的光明前景(self-supervised ViT holds promise for the future).
做实验的时候,ViT的configurations是基于BERT,“Base" and "Large" models 采用BERT的。fine-tuning accuracies反应了模型在各自的数据集上fine-tune之后的性能。后面这个few-shot accuracies就不太理解了。few-shot accuracies are obtained by soling a regularized least-squares regression problem that maps the (frozen) representation of a subset of training images to \({[-1,1]}^K\) 目标vectors。 this formulation allows us to recover the exact solution in closed form.。有时候用linear few-shot accuracies for fast on-the-fly evaluation where fine-tuning would be too costly.
- ViT 似乎在尝试的范围内,没有saturate,motivating future scaling efforts.
- NLP的成功不仅在于Transformer的scalability,也在于 large scale self-supervised pretraining.
另外一个挑战是:继续探索 self-supervised pre-training 方法。最初的实验表明自监督预训练带来的提升。最后,scaling of ViT would likely lead to improved performance.
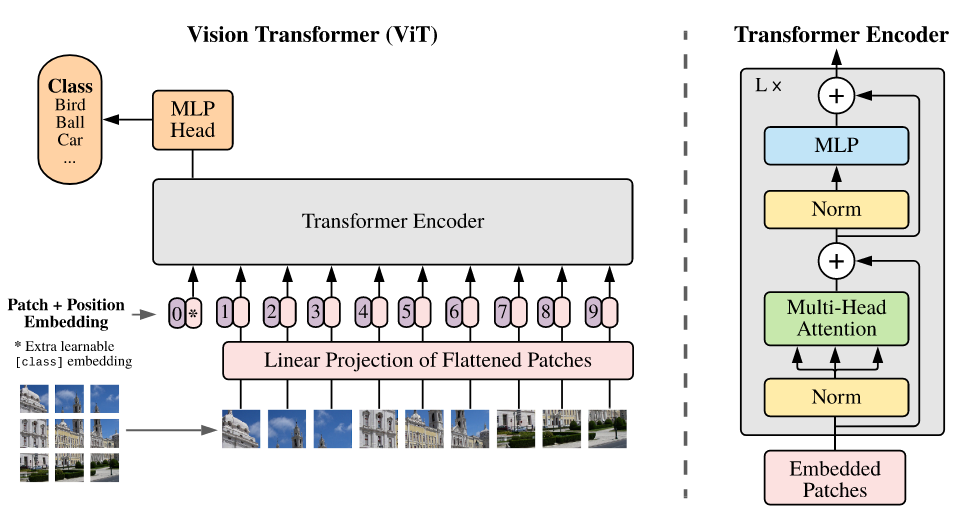 $ Fig.1^{[1]} $: Model overview. We split an image
into fixed-size patches, linearly embed each of them, add position
embeddings, and feed the resulting sequence of vectors to a standard
Transformer encoder. In order to perform classification, we use the
standard approach of adding an extra learnable “classification token” to
the sequence. The illustration of the Transformer encoder was inspired
by Vaswani et al. (2017)
$ Fig.1^{[1]} $: Model overview. We split an image
into fixed-size patches, linearly embed each of them, add position
embeddings, and feed the resulting sequence of vectors to a standard
Transformer encoder. In order to perform classification, we use the
standard approach of adding an extra learnable “classification token” to
the sequence. The illustration of the Transformer encoder was inspired
by Vaswani et al. (2017)