SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[1]
作者是何恺明,张祥宇,任少卿和孙剑。论文引用[1]:He, Kaiming et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” IEEE Transactions on Pattern Analysis and Machine Intelligence 37 (2014): 1904-1916.
Time
- 2014.Jun
Key Words
- spatial pyramid pooling
动机
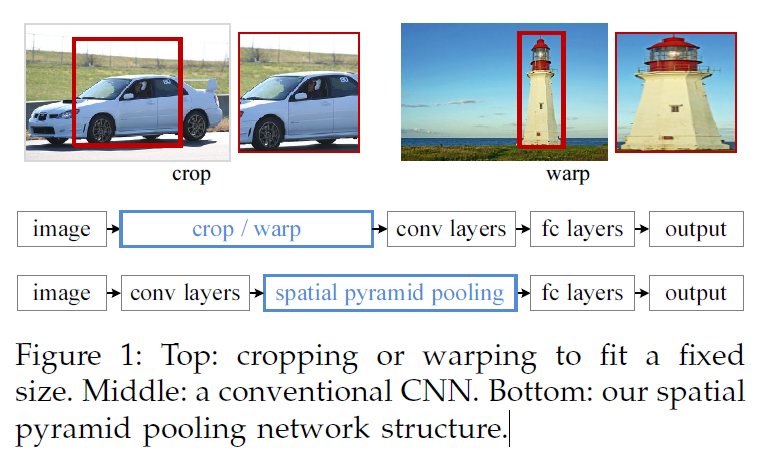
- 当前的CNNs要求输入图片有fixed-size, 这个要求可能会降低recognition accuracy for images or sub-images of an arbitrary size.
总结
之前的CNNs有一个问题:要求固输入的图片时固定的尺寸,限制了aspect ratio and scale of input image. 当输入任意尺寸的图片时,当前的方法会通过crop,warp等方式将图片弄成fixed-size。crop/warp可能会造成目标的确实或者可能的形变。 fixing input sizes 忽视了issues involving scales。CNN中的fc layers 需要固定长度的输入,这个存在于深度的网络中。
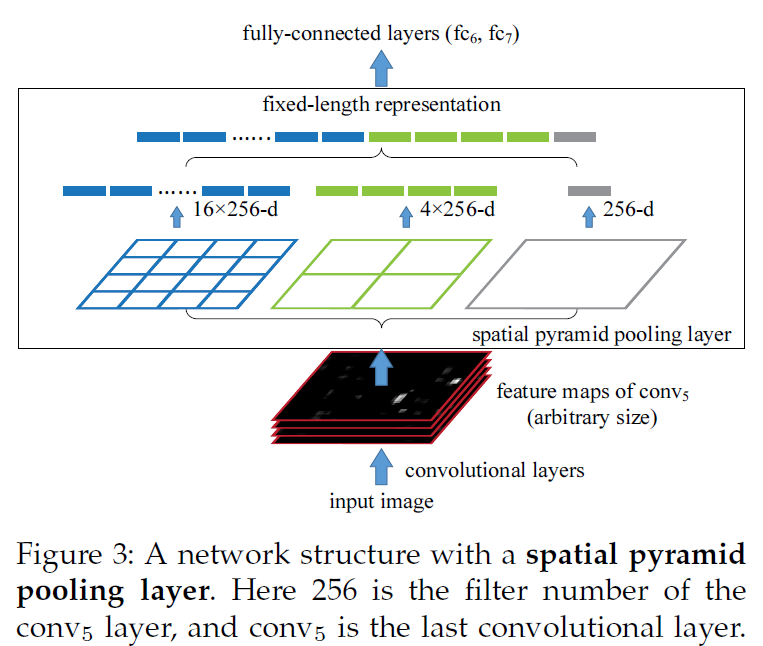
在最后一个卷积上加一个SPP layer, 能够产生a fixed-length representation regardless of image size/scale,pyramid pooling is also robust to object deformations。换句话说:这个是做了一个information aggregation。
SPPNet,从整个图片中只计算一次feature map, 然后pool features in arbitrary regions to generate fixed-length representations for training detecotors. 这个方法避免了重复计算conv features.
Spatial pyramid pooling,是Bag-of-words(BoW)的扩展,SPP 用multi-level spatial bins, while sliding window pooling uses only a single window size.
spatial bins have sizes proportional to the image size, 因此bins的数量是固定的,这与之前的sliding window pooling不一样(sliding windows 的数量依赖于input size)