FairMOT
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking[1]
作者是来自华科和微软的Yifu Zhang等人。论文引用[1]:Zhang, Yifu et al. “FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking.” International Journal of Computer Vision 129 (2020): 3069 - 3087.
Time
- 2021.Oct
Key Words
- object detection and re-id in a single network
- 一句话来说:就是在single network中,结合detection和re-id的多任务学习,同时避免了之前的基于anchor的reID feature的带来的ambiguity和feature conflict的问题。FairMOT的detection branch是基于CenterNet、anchor-free的方式,re-ID 是feature dimension为64,实现了更好的效果。
总结
- MOT在CV中是一个重要的任务,将MOT表述为单个网络中的object detection和 re-id的多任务学习 is appealing,因为它运训两个任务的联合优化,计算效率高。然而,作者发现,两个任务倾向于彼此竞争,需要谨慎处理。特别地,之前的任务通常将Re-id作为一个附属任务,它的精度被之前的detection task严重影响。因此,网络会偏向detection,对 re-id not fair。为了解决这个问题,作者提出了一个简单有效的方法,称之为 FairMOT,基于CenterNet,注意到,这不是简单的centerNet和Re-id的结合。相反,作者展示了很多细节的设计,这些对实现一个好的结果很重要。这个方法在检测和跟踪上实现了很好的精度。
MOT是一个长期存在的目标,这个目标是估计视频中感兴趣objects的轨迹。大多数现有的方法尝试通过两个独立的模型来处理这个问题,detection model首先检测每一帧中的objects,然而association model提取每个bboxes区域的reid特征,根据一定的metrics,将detections连接到现有的tracks或者创建一个新的track。在object detection上有很多的进步,reid提高了tracking的精度,然而,这two-step方法会有scalability的问题,他们不能实现实时的推理速度,两个两个网络没有共享参数,它们需要将re-id 模型应用到每个bbox。随着多任务学习的成熟,one-shot trackers用单一的网络来估计objects和学习re-id特征吸引了很多的注意力。例如,有人在Mask R-CNN上加了一个re-id分支来提取每个proposal的re-id特征,通过re-use backbone feature for re-id,,能够减少推理时间,但是性能下降了很多,实际上,detection accuracy仍然是好的,但是跟踪性能下降了很多,例如ID switches的数量增加了很多。这个结果表明,将两个任务结合是non-trivial,需要仔细的设计。
在本文中,作者研究了失败的原因,提出了一个简单有效的解决办法,失败的原因有三个。第一个问题是由anchors造成的,anchors是用于object detection的,然而,作者发现,anchors不适用于提取re-id特征,首先,anchor-based one-shot trackers例如Track RCNN忽视了re-id,因为它们需要anchors首先来检测目标,然后基于检测的结果提取re-id特征。因此,当两个任务之间存在竞争的时候,它会favor detection 任务,在训练re-id特征期间,anchors也会引入ambiguity,因为一个anchor可能对应多个identities,多个anchors可能对应一个identity。第二个问题是由两个task之间的feature sharing造成的,detection task和re-id task 是两个不同的任务,它们需要不同的features,通常,re-id features需要更多low-level的features来区分同一类的不同instances,然而detection features need to be similar 对于不同的实例。在one-shot trackers中共享的features会导致feature conflict,因此会降低每个人物的性能。第三个问题是由feature dimension造成的,re-id 特征的维度通常高达512或者1024,高于object detection,作者发现维度之间的差异会损害两个人物的性能,更重要的是,作者实验表明:学习一个低维的re-id feature对于joint detection and re-id 网络实现了更高的跟踪的精度和效率,这是一个通用的规律,这也表明MOT任务和re-id任务之间的不同,在MOT中被忽略了。
在这个工作中,作者提出了一个简单的方法,称之为FairMOT,优雅地处理了这三个问题,FairMOT建立在CenterNet上,特别地,detection和re-id任务在FairMOT中同等对待,不同于之前的detection first, re-id secondary。值得注意地是,不是CenterNet和re-id的简单结合。下图展示了FairMOT,有一个简单的网络,包含两个同样的branches for detecting objects和提取re-id特征。受别人工作的启发,detection branch是 anchor-free的,能够估计object centers和sizes represented as position-aware measurement maps。类似地,re-id分支为每个像素估计一个重识别特征,以描述以该像素为中心的目标特征。注意到这两个分支is homogeneous,不同于,实现了detection和re-id之间的 trade-off。它揭示了多目标跟踪(MOT)中检测与重识别(re-id)之间的关系,并为设计一体化视频跟踪网络提供了指导。作者的贡献如下:
- 表明了基于anchor的、流行的MOT架构在学习有效地re-id 特征上是有局限的。这个问题严重地限制了跟踪的性能。
- 提出了FairMOT,来解决fairness问题,FairMOT建立在CenterNet上,尽管采用的techniques大多数并不novel
最好的MOT方法通常是采用tracking-by-detection范式,首先检测每一帧的目标,然后将它们随着时间关联起来,将这些现有的工作分为两位,基于它们是用单个模型还是sperate model建检测目标和提取关联特征。
Detection and Tracking by Separate Models:
- detection: 现有的benchmark datasets例如MOT17提供了DPM、FasterRCNN、SDP的检测结果,这样的网络关注于tracking,能够在相同的object detections上公平地对比。一些工作用一个大的私有的行人检测数据集来训练FasterRCNN,得到了更好的检测性能。一些工作用了更强的detectors,提高了检测性能。
- Tracking:
大多数现有的工作关注于tracking,根据用于association的cues的类型,将它们分为两类:
Location and Motion Cues: SORT首先用了Kalman filter来预测tracklets的future locations,计算它们和detections的overlap,然后用匈牙利算法给tracklets分配detections,IoU-tracker直接计算tracklets和detections之间的overlap,不用Kalman filter来预测future locations。这个方法速度快,当object motion很小的时候效果很好,SORT和IoU-tracker用的很多。然而,在拥挤场景和快速运动的时候,可能遇到挑战。一些工作利用复杂的single object tracking 方法,来得到准确的object locatinos,降低false negative,然而,这些方法当有很多人的时候,特别慢。为了解决轨迹碎片的问题,有人提出了motion evaluation network来学习long-range features of tracklets用于association,MAT是一个增强的SORT,对camera motion进行建模,用dynamic windwos用于long-range re-association。
Appearance Cues based methods: 一些工作提出了将image regions of detections,给到reid网络,来提取image features,然后计算tracklets和detections之间的相似度,用匈牙利算法完成assignment。这个方法对于快速运动和遮挡是鲁棒的。特别地,因为appearance features是相对稳定的,它能够初始化lost tracks。也有一些工作聚焦于增强appearance features,有人提出了一个在线appearance learning方法,来处理appearance variations;有人利用body pose features来增强appearance features。一些方法提出融合多个cues来得到更可靠的相似度,MOTDT提出了层次化的数据关联,当appearance features不可靠的时候,用IoU来关联目标。一些工作也提出用更复杂的关联策略例如group models和RNNs。
offline 方法:offline methods(batch methods) 通过在整个sequence中进行全局优化,实现了更好的结果。例如,Zhang等人构建了一个graphical model,在所有帧中表示detections,optimal assignment是用min-cost flow来解决的,利用图的特殊结构,比线性规划快很多。有人将data association视为一个flow optimization任务,用K-shortest paths 算法来解决,加速了计算,减少了参数地调整。有人将MOT表示为一个continuous energy的最小化问题,聚焦设计energy functin,这个energy依赖于所有帧中的所有目标的location和motion。MPNTrack提出了可训练的graph neural networks,来对entire set of detections进行全局的关联,使MOT完全differentiable。Lif_T将MOT表述为一个lifted disjoint path问题,并引入了用于长时间跨度交互的提升边,这显著减少了身份切换和重新识别丢失的情况。
Advantages and Limitations:对于通过separate models进行detection和tracking的方法,主要的优势是它们能够对于每个任务,develop最合适的model,不需要妥协。另外,根据detected bboxes,将image 裁成patches,然后在估计re-id 特征之前resize。这能够处理variations of objects,因此,这些方法实现了很好的性能。然而,它们通常比较慢,因为两个任务需要分别处理,很难实现video rate inference。
Detection and Tracking by a Single Model:随着多任务学习的成熟,用单个网络的joint detection和tracking吸引了很多的注意。下面将他们分为两类:
Joint Detection and Re-ID:第一类的方法在single network中进行object detection和re-id feature extraction,为来降低inference time,例如Track-RCNN在Mask RCNN上加了一个reid head,回归一个bbox,每个proposal 一个re-id feature。类似地,JDE建立在YOLOv3上,实现了near video rate inference。然而,这些one-shot trackers的精度通常低于two-steps的。
Joint Detection and Motion Prediction:第二类方法是在single network中学习detection和motion features, D&T提出了Siamese 网络,输入相邻帧,预测bbox之间的位移。Tracktor直接利用bbox regression head来传播region proposals的identities,因此去掉了box association。 Chained-Tracker提出了用adjacent frame pair的端到端的模型,作为输入,产生表示相同目标的box pair。这些box-based的方法假设假定帧之间的bbox有大的overlap,在low frame rate 视频中是不成立的。不同于上述的方法,CenterTrack预测object center的位移,通过这些points的距离来进行关联。它还提供了tracklets作为网络的一个额外的point-based heatmap输入,从而能够匹配任何位置的对象,即使这些框完全没有重叠。然而,这些方法仅关联相邻帧的目标,没有重新初始化lost tracks,处理遮挡的情况有难度。作者的工作属于第一种,研究了为啥one-shot trackers关联性能上退化,提出了一个简单的方式来解决问题。作者展示了tracking accuracy不需要heavy engineering efforts来提高。当前的工作CSTrack从特征的角度,旨在缓解两个任务的conflicts,提出了一个cross-correlation network module 使模型学到task-independent representations。不同于CSTrack,作者的方法尝试从三个角度解决这个问题。CeterTrack和作者的工作也相关,因为它也用了center-based object detection framework,但是CeterTrack没有提取appearance features,仅关联相邻帧的frames,相比之下,FairMOT能够进行long-range association with appearance features,处理遮挡的情况。
Multi-task learning:多任务学习有很多的文献可能用于平衡object detection和re-id feature extraction tasks。Uncertainty用task-independent uncertainty来自动化地平衡single-task losses。MGDA通过在task-specific gradients中发现common direction,来更新网络权重。GradNorm通过模拟task-specific gradients,使其具有相似的大小,控制多任务网络的训练。
Video object detection:它和MOT相关,利用tracking来提高object detection的表现。尽管这些方法没有在MOT数据集上进行评估,一些思路可能是有价值的。Tang等人检测object tubes in videos,旨在增强classification scores。对于小目标的detection rate提高了很多。这些tube-based的方法的局限是它们在处理视频中的大量目标的时候非常慢。
Unfairness Issues in One-shot Trackers:在这个部分,讨论现有one-shot trackers中的3个unfairness的问题,通常导致退化的跟踪性能。
- Unfairnes Caused by Anchors:现有的one-shot
trackers例如TrackRCNN和JDE使ancho-based,因为它们是直接从基于anchor的检测器例如YOLO和Mask
RCNN修改来的。然而,作者发现,anchor-based的设计不适合学习re-id
features。会导致大量的ID switches,尽管detection结果很好。
Overlooked re-id task:Track RCNN 以级联的方式进行操作,首先估计object proposals,然后pool features from them,来估计对应的re-id features。re-id features严重依赖于训练期间的proposals的质量。因此,在训练阶段,model会偏向于精确地object proposals而不是high quality re-id features。因此标准的detection first, re-id secondary的设计使得re-id 网络没有fairly learned。
one anchor corresponds to multiple identities:基于anchor的方法用ROI-Align从proposals中提取特征。大多数的sampling locations in ROI-Align可能属于干扰的instances或者background,因此,提取的特征不是最优的。相反,在single point提取特征效果更好。
multiple anchors correspond to oen identity:多个adjacent anchors,可能对应不同的image patches,只要它们的IoU足够大,可能会估计same identity。这会在训练中引入ambiguity。另一方面,当image 经历一些干扰的时候,同样的anchor可能会去estimate 不同的identities。另外,object detection中的feature maps通常是down-sampled 8/16/32 倍,来平衡速度和精度。这对于object detection来说是可接受的,但是对于学习re-id features是too coarse,因为features extracted at coarse anchors可能无法和object centers对齐。
Unfairness Caused by Features:对于one-shot trackers,大多数的features在object detection和re-id task之间是共享的。但是它们需要来自不同的layers的features来实现最好的结果。特别地,object detection 需要deep features来估计object classes和positions,但是re-id 需要 low-level appearance features,来区分同一类的不同的instances,从多任务损失优化的家督,detection和re-id的优化目标是冲突的,因此,需要平衡两个任务之间的损失优化策略。
Unfairness Caused by Feature Dimension:之前的re-ID 的工作通常是学习高维特征,实现了很好的结果,然而,作者发现,学习低维特征对于one-shot MOT更好:1. 高维的re-id features损害了object detection 精度,由于两个任务之间的竞争,对于最后的tracking accuracy是由伤害的。因此,考虑到object detection中的feature dimension是很低的,作者提出学习低维的re-id 特征来平衡两个任务; 2. MOT任务不同于re-ID 任务,MOT任务只进行两个连续帧之间的one-to-one matchings,re-id 任务需要将一个query和大量的candidates进行match,需要更多的discriminative和高维的re-id features,因此,MOT不需要高维的features;3. 学习低维的re-id features提高了推理速度
- Unfairnes Caused by Anchors:现有的one-shot
trackers例如TrackRCNN和JDE使ancho-based,因为它们是直接从基于anchor的检测器例如YOLO和Mask
RCNN修改来的。然而,作者发现,anchor-based的设计不适合学习re-id
features。会导致大量的ID switches,尽管detection结果很好。
FairMOT结构:
- Backbone:采用ResNet-34作为backbone,为了实现速度和精度的平衡。用了增强版本的Deep Layer Aggregation(DLA),来融合multi-layer features。不同于原始的DLA,它有更多的skip connections between low-level和high-level,类似于Feature pyramid Network。另外,在所有up-sampling modules中的卷积层被deformable conv代替,能够动态地同届感受野。这些修改有益于缓解alignment问题。最后的模型称之为DLA-34。
- Detection Branch:Detection branch 是建立在CenterNet基础上的,但是其它的anchor-free的方法也用了。特别地,用了三个parallel heads加在DLA-34上,来估计heatmaps、object center offsets和bbox sizes。每个Head用了 \(3 \times 3\) conv。
- Heatmap head:该head负责估计物体中心的位置。基于热图的表示方法是landmark point estimatin task的实际标准。特别地,heatmap的维度是 $1H W $。如果热图中的某个位置与真实物体中心重合,则该位置的响应值预期为一。对于每个GT box,计算object center,然后,通过divide the stride得到feature map上的位置,(x,y) 位置上的heatmap的响应通过公式计算,loss function定义为pixel-wise logistic regression with focal loss。
- Box Offset and size heads:box offset head 旨在定位objects。因为final feature map的stride是4,将会引入quantization errors up to four pixels。该分支为每个像素估计相对于物体中心的连续偏移量,以减轻下采样的影响。box size head负责估计每个位置上目标框的高度和宽度。
- Re-ID branch。Re-ID branch旨在产生能够区分目标的features。不同目标之间的affinity应该小于相同目标之间的。为了实现这个目标,用了一个conv layer on top of backbone features来提取re-id features for each location,中心位于 \((x,y)\) 的 re-ID feature 能够从feature map中提取出来。通过一个classification task来学习re-id features,所有相同identity的object instances in the training set被视为同一类,对于每个GT box in the image,得到heatmap上的object center,提取re-ID feature,用一个全连接层和一个softmax操作,将其map到一个class distribution vector。在训练期间,只有位于object centers的identity embedding vectors用于训练。
Training FairMOT:通过将losses加到一块,联合训练detection和reid branches。特别地,用了uncertainty loss,来自动地平衡detection 和re-id tasks。
\(w_1\) 和 \(w_2\) 是可学习的参数,来平衡两个任务。具体而言,给定一张包含若干物体及其对应ID的图像,我们生成热图、框偏移和size maps以及物体的one-hot编码类别表示。这些将与估计的度量值进行比较,以获得损失,从而训练整个网络。 除了以上的标准的训练策略,还提出了single image training method,来训练FairMOT
Network Inference:网络输入 \(1088 \times 608\),和之前的JDE的工作一样,在predicted heatmap上,进行NMS,来提取peak keypoints,NMS是通过简单的 \(3 \times 3\) max pooling操作来实现,保留heatmap scores大于阈值的keypoints的位置。然后,基于估计的offsets和box sizes计算对应的bboxes。在estimated object centers上提取identity embeddings。
- Online association:follow MOTDT,用一个层次刷的online data association方法,首先基于第一帧的detected boxes来初始化tracklets。然后,在接下来的帧中,将detected boxes连接到现有的tracklets中,用两阶段的方法。在第一阶段,用Kalman filter和re-id features来得到initial tracking results。特别地,用Kalman filter来预测tracklet locations,计算Mahalanobis distance between predicted and detected boxes。融合Mahalanobis距离和cosine distance。用匈牙利算法完成第一阶段的匹配。 在第二阶段,对于unmatched detections和tracklets,尝试根据它们之间的boxes来进行匹配。特别地,将matching 阈值设为 0.5,更新tracklets的appearance features in each time step,来处理外观变化。最后,初始化unmatched detections作为新的tracks,保存unmatched tracklets for 30 frames,防止它们重新出现。
从之前为啥one-shot 方法不能实现和two-step方法类似的结果开始,作者研究了在object detection用的anchors和identity embedding是退化的主要原因。特别地,多个临近的anchors,对应于一个目标的different parts,可能responsible for estimating the same identity,可能造成网络训练的模糊。作者还发现,detection和reID任务之间的feature unfairness issue和feature dimension issue。通过解决这些问题,作者提出了FairMOT。
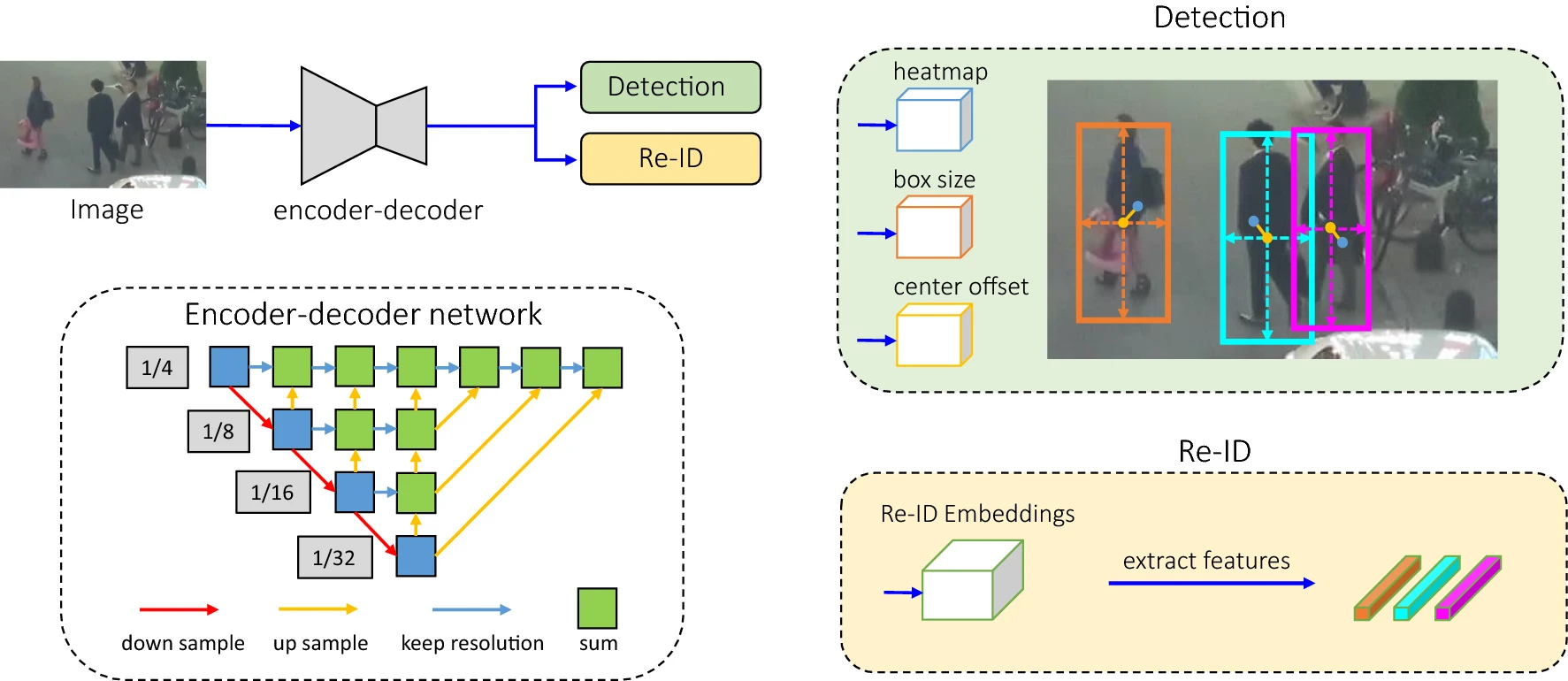 \(Fig.1^{[1]}\) Overview of
MOT,输入的image首先给到一个encoder-decoder network,来提取high
resolution feature map,然后,用了两个相同的分支用于检测和提取reid
features,在predicted object centers的features用于tracking。
\(Fig.1^{[1]}\) Overview of
MOT,输入的image首先给到一个encoder-decoder network,来提取high
resolution feature map,然后,用了两个相同的分支用于检测和提取reid
features,在predicted object centers的features用于tracking。
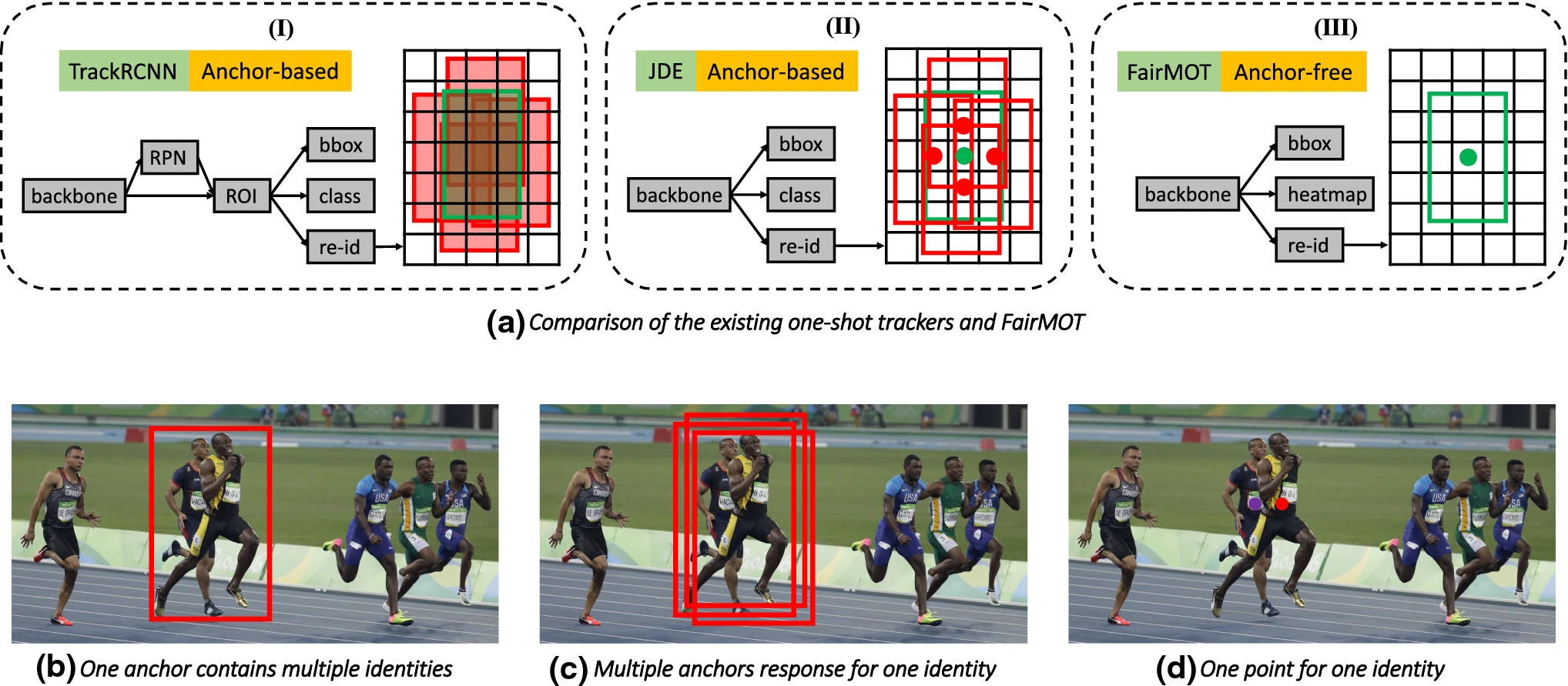 \(Fig.2^{[1]}\)
Track RCNN将detection作为主要的task,reID作为次要的。Track RCNN
和JDE都是anchor-based的,red boxes表示positive anchors,green boxes表示
target objects,三种方式提取re-ID的特征不同,Track RCNN提取所有positive
anchors的reid features,JDE提取reid features at the centers of all
positive anchors。FairMOT提取object center的reid features。b.
红色的anchor 包含两个不同的instances,因此,它会forced
来预测两个冲突的classes。c. 三个不同的的anchors with different image
patches 用于预测相同的identity,FairMOT仅提取位于object center的re-id
features,能够幻剑b和c中的问题。
\(Fig.2^{[1]}\)
Track RCNN将detection作为主要的task,reID作为次要的。Track RCNN
和JDE都是anchor-based的,red boxes表示positive anchors,green boxes表示
target objects,三种方式提取re-ID的特征不同,Track RCNN提取所有positive
anchors的reid features,JDE提取reid features at the centers of all
positive anchors。FairMOT提取object center的reid features。b.
红色的anchor 包含两个不同的instances,因此,它会forced
来预测两个冲突的classes。c. 三个不同的的anchors with different image
patches 用于预测相同的identity,FairMOT仅提取位于object center的re-id
features,能够幻剑b和c中的问题。