featureSORT
FeatureSORT: Essential Features for Effective Tracking[1]
作者是来自韩国的Hamidreza Hashempoor等人。论文引用[1]:Hashempoor, Hamidreza et al. “FeatureSORT: Essential Features for Effective Tracking.” ArXiv abs/2407.04249 (2024): n. pag.
Time
- 2024.July
Key Words
- multiple feature modules
- measurement-to-track associated distance function
- Global linking for missing association
- Gaussian Smoothing Process for missing detection
- 一句话来说:在DeepSORT的基础上,结合了多种信息,Style、Direction、BoT(ReID)、motion state等,在后处理上,增加了Global Linking和GSP,增强了tracker的性能。
总结
- 在这个工作中,我们提出了一种新型跟踪器,专为在线多目标跟踪设计,在保持高效性的同时注重简洁性。作者提供了多个feature modules,每个代表以各种appearance information。通过集成这些不同的appearance features,包括衣服颜色,style,target direction,还有一个ReID网络用于embedding extraction,作者的tracker显著地提高了跟踪精度。另外,作者引入了更强的detector,提供了先进的后处理方法,能够进一步提高tracker的性能。在实时operation的时候,建立measurement-to-track的关联距离函数,包括IOU, Direction, color, style, 和edge(ReID features) similarity information,每个metric的计算是分开的。有了这个feature-related distance function,在更长的遮挡的时候,是有可能跟踪objects的,能够保持id切换相对比较低。大量的实验评估表明在跟踪精度和可靠性上有了显著的提升。具体表现为身份切换次数减少、遮挡处理能力增强。这些进展不仅推动了目标跟踪领域的技术前沿,更为未来需要高精度与高可靠性的研究及实际应用(如自动驾驶、视频监控等)提供了新的探索方向与技术路径。
MOT的目的是检测和跟踪每一帧中的所有目标。这个任务在视频理解中很重要。由于视频中目标较多,检测到的bboxes因为detectors容易出现不完美的预测而导致不精确,另外,MOT方法,需要处理true positive, false positive balance in detection boxes,来去掉低置信度的detection boxes,仅处理高置信分数的objects。由于近些年detection modules的涌现,处理这个问题是可行的。TbD是现在针对MOT最有效的范式,因为MOT严重依赖detection和object ReID,大多数的TbD方法会投入在detectors上ReID models上,来增强MOT的性能。这些方法首先提取appearance 和motion information,然后用matching 算法将detections分配给现有的tracklets。
沿着同样的路线,本文展示了一个简单有效的MOT的baseline称之为FeatureSORT,提高了经典的TbD tracker, DeepSORT,它是将deep learning集成到MOT中的基本方法,DeepSORT是一个简单、可解释的、有效的模型,在很多计算机视觉任务中有广泛地应用。尽管DeepSORT因其传统的跟踪算法而受到一些批评,但它具备通过融合新特性与推理方法进行增强的巨大潜力。具体来说,首先,提供一个更强的detector with better embedding for DeepSORT;其次,除了ReID features,给DeepSORT加上separated feature modules,每一个代表pedestrian targets的一种feature。尽管ReID networks用于提取embedding information,这个information太generic,可能无法囊括target的整个的appearance information,colors, direction, style等;另外,作者也包含了先进的后处理方法,来进一步提高DeepSORT的性能。有简单有效的components增强DeepSORT,构建了FeatureSORT。FeatureSORT的动机总结如下:
- 通过构建模块化、基于特征的跟踪框架,以解决现有TBD(Track-Before-Detect)跟踪器的局限性。我们的目标是建立一个多功能基线框架,使其能够灵活适配并优化各类跟踪方法。
- 为了增强MOT系统在不同环境中的适应性和有效性。FeatureSORT旨在构建一个新的benchmark用于performance comparison。
- 旨在展示如何通过策略性选择与应用先进的推理及后处理方法,显著提升跟踪精度与效率。
在MOT的语境中,两个主要的挑战是missing association and missing detection。Missing association的本质是相同的object出现在多个track trajectory中,这个问题在online trackers中普遍存在,因为它们不能得到用于关联的全局信息。第二个挑战missing detections,就是false negatives。是指object被错误地分类为了background,这个误分类可以归结为遮挡和low resolutions这样的因素。
在线跟踪算法运行后,每个目标的轨迹可能因检测错误或目标遮挡而被分割成多个短轨迹段和长时间丢失的关联轨迹段。为了将这些trajectories合并为一个trajectory,以离线的方式采用global information。global link和GIAO tracker一样,作者提出了一个复杂的global link 算法,用提高的ResNet50-TP model编码tracklet appearance features,spatial 和temporal costs关联tracklets。尽管这个方法计算量大,基于global information的连接tracklet通常是在得到所有的trackelts之后的,以离线的方式进行的。
为了处理missing-detection issue,采用线性插值的方法,在得到一个轨迹之后,missing frames被线性插值。然而,它在插值的时候忽视了motion information,限制了插值的position的精度。为了缓解这个问题,结合Gaussian Smoothing Process用于interpolation。GSP能够通过结合过去和未来观测结果对每个观测值进行修正,从而提升模型性能。linking和插值是轻量化、即插即用的,不依赖模型的后处理方法,使得它们对所有的跟踪算法都适用。在作者的实验中,用这些后处理方法,增强了tracker的性能。
尽管最先进的tracker算法依赖于离线的后处理来实现很好的表现,作者更关注于online tracking。因此,作者展示了结果大多数是online场景的,假设后处理是不可行的。大量的实验表明提出的feature modules能够在FeatureSORT上有很好的提升。通过将detector结合feature modules,在多个数据集上实现了SOTA。作者的贡献如下:
- 提出了FeatureSORT,用先进的detection module和feature modules,以及一些推理策略,增强了DeepSORT。
- 为了解决missing association和detections的问题,作者提出了Global Linking和GSP算法,能够离线地纠正tracklet trajectory。Global Linking和GSP可以插到多个trackers,来提高性能。
在MOT领域中,TbD模型是基石方法。这些模型首先通过检测帧中的objects,然后关联这些detections,来得到轨迹,TbD模型的有效性依赖于association 机制,基于多种信息尝试逐帧匹配detections。这个process充满挑战,包括遮挡,快速移动的objects还有appearance或者illumination的变化。根据用于association的信息的类型,将TbD模型分为三类。这个分类不仅有助于理解现有方式的情况,也能highlight方法的evolution。
Location and Motion information based Methods:SORT利用Kalman filter来估计tracklets下一个locations,它tracklets和当前detections的overlap,利用一个matching算法将detections分配给tracklets。IoU-tracker计算上一帧中的tracked 的object的位置和detections之间的overlap,没有依赖于Gaussian filtering来估计next locations。SORT和IOU-tracker都是广泛应用的,因为它们的简单。然而,它们可能不是最优的选择,例如拥挤或者快速移动。一些工作,考虑复杂的single-object tracking方法来得到精确地object locations。这些方法比较慢。特别是当有很多的objects需要被tracked的时候,为了处理missing trajectories和fragments of tracklets造成的挑战,有人用一个motion evaluation network,学习tracklets的feature,促进有效关联。MAT是SORT的改进版本,引入了camera motion modeling,采用dynamic windows用于long-range association。
Appearance information based Methods:最近的方法考虑基于detection bboxes,crop images,然后将cropped image给到ReID网络中,提取image embeddings,定义了一个similarity metric来决定tracklets和detection embeddings之间的相似度,用一个matching算法来完成assignment。这个方法擅长处理快速运动和遮挡的场景。特别地,由于object features的stability,这些models也能重新初始化lost tracks。另外,一些研究也关注于提高appearance embeddings。例如,有人引入了在线学习的appearance learning method来解决appearance changes。有人引入了body pose features来提高appearance embedding。一些算法,例如有人建议结合多种类型的information(motion, appearance, location) 来得到更精确的similarity metric。MOTDT引入了层次化的data association policy,当appearance features被认为不可靠的时候,利用IoU将objects分配给tracklets。另外,一些工作提出了更复杂的assignemnt 策略,例如用RNN用于assocaition purposes。
Offline Methods:offline methods,也成为batch methods,通过在整个trajectories上的global optimization,实现更好的结果。例如,有人用带nodes的图模型来表征detections。它们用最小成本流算法进行搜索,利用graph的特点来达到最优解决方案,超过了线性规划的效率。也有人将data assigning视为flow optimization任务,明显地加速了计算。Milan等人通过将MOT表述为一个continuous energy function的最小化,来解决这个问题,寻找一个合适的energy function。这个energy function考虑locations和所有objects的motions,还有相关的constraints。MPNTrack包含可训练的graph neural networks来进行整个detections集合的全局assigning。也有人将多目标跟踪(MOT)问题定义为提升的不交路径问题(lifted disjoint path problem),并通过引入边(edges)建模long-range时序交互。该技术显著减少了ID切换问题,同时能够对丢失的轨迹进行重新识别。
DeepSORT利用两个不同的branches来提取信息:一个是appearance,另一个是motion,对于每一个frame,appearance branch利用一个appearance descriptor,这个是在MARS person ReID数据集上预训练的,来提取appearance embedding。这个方法利用了feature bank的机制来存储每个tarcklet的last frame的embedding。在检测到一个new object的时候,第i个tracklet的feature bank和第j个detection的feature vector的最小余弦距离的计算如下:
\[dist(i,j)=min\{1-\langle\mathbf{e}^{(i)},\mathbf{f}^j\rangle|\mathbf{e}^{(i)}\in\mathcal{E}^{(i)}\}\]
余弦距离在matching cost中用来assignment purposes。这个motion branch用Gaussian filtering approach来估计当前帧中的tracklets的位置。Gaussian filtering(Kalman filter)在两个阶段中工作:state prediction和state update。在state prediction stage,它估计当前的state:
\[\mu(t|t-1)=\mathbf{G}(t)\mu(t-1|t-1)\] \[\mathbf{P}(t|t-1)=\mathbf{G}(t)\mathbf{P}(t-1|t-1)\mathbf{G}^T(t)+\mathbf{Q}(t)\]
\(G(t)\) 是线性state transition matrix。\(Q(t)\) 是process noise的协方差。\(\mu(t-1|t-1)\) 和 \(P(t-1|t-1)\) 是在时刻t-1的fitlered state的mean和covariance。\(\mu(t|t-1)\) 和 \(P(t|t-1)\) 是在时刻t的预测的mean和covariance states。在state update stage,Kalman gain的计算如下:
\[\mathbf{K}(t)=\mathbf{P}(t|t-1)\mathbf{H}^T(t)\left(\mathbf{H}(t)\mathbf{P}(t|t-1)\mathbf{H}^T(t)+\mathbf{R}(t)\right)^{-1},\]
\(H(t)\) 是emission matrix,然后,时刻t的filtered state如下: \[\mu(t|t)=\mu(t|t-1)+\mathbf{K}(t)\left(\mathbf{z}(t)-\mathbf{H}(t)\mu(t|t-1)\right)\] \[\mathbf{P}(t|t)= \begin{pmatrix} \mathbf{I}-\mathbf{K}(t)\mathbf{H}(t) \end{pmatrix}\mathbf{P}(t|t-1)\]
\(z(t)\) 是时刻t的measurement。有了tracks的motion state和new bboxes,DeepSORT用欧式距离来measure dissimilarity between them。这个算法考虑了motion distance作为一个标准来过滤掉不可能的assignments。随后,用matching cascade algorithm将assignment任务分解为多个子问题,而不是全局的分配问题。这个策略会在匹配的时候优先处理更常见的objects。每个关联的子问题通过匈牙利算法解决。
FeatureSORT:在这个部分,提出了很多方法将DeepSORT更新到FeatureSORT,具体地说,这个部分没有任何新的方法。而是,通过多种方法来增强DeepSORT,构建一个更robust的MOT的基线。作者的增强包含了更强的detection model,有意义的feature modules的集成来增强tracking performance。新的推理策略的引入,以及执行,这些增强为有效地object tracking提供了必要的工具。整个的架构如下图所示。
- Strong detector:通过部署高性能的detector YOLOX,得到了更多精确的detections,这是实现可靠跟踪的mandatory factor
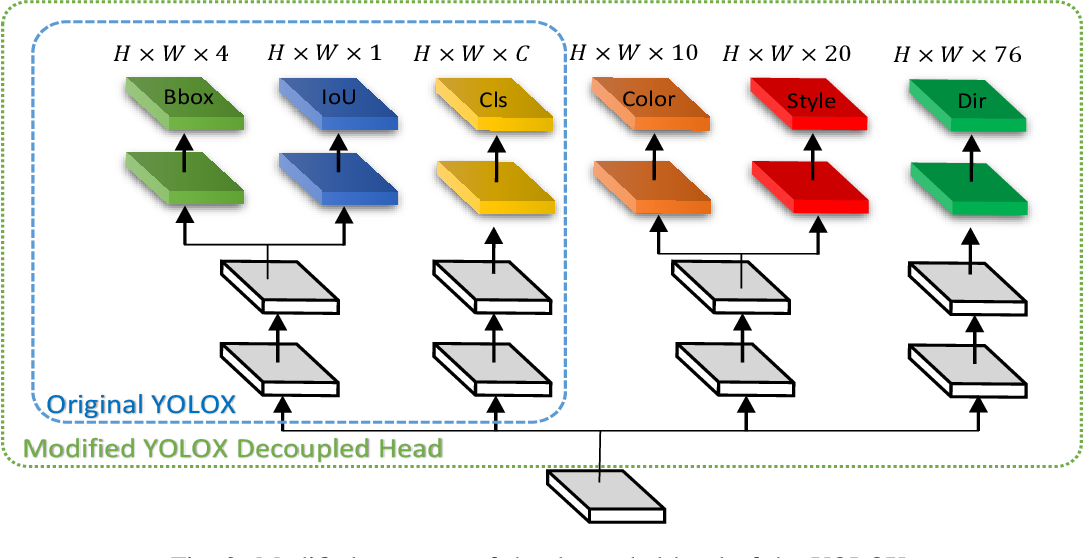
- feature-based modules:为跟踪算法提供feature-based的模块,使整个系统具备更强的嵌入信息,同时为行人重识别(ReID)和跟踪一致性提供更多线索。对于像遮挡、不完美的detections等场景很有用。YOLOX的结构设计为定位和分类任务分别提供独立的输出分支,从而构建完整的检测流程。作者沿着localization和classification heads添加了两个separate heads。一个head用于提取color和style classification的embeddings,另一个提供direction的classification。为了保持detector的高性能,在detection training阶段之后,冻结了backbone, localization head和classification head,分开训练feature module heads,这个YOLOX解耦的、修正的结构如图所示。
- Clothes Color:首先,为图片做color annotation,分为10类:Black、Blue、Green、Magenta、Pink、Purple、Red、Yellow、White、Navy。接下来,将颜色进行编码为一个vector,表示每个objects的clothes的颜色。例如:\(gtc=[[1 0 0 1 0 0 0 0 0 0]]\) 意味着输出的color是green和black,通过考虑交叉熵损失来完成训练。 \[\mathcal{L}_{color}(\mathbf{gtc},\mathbf{c})=-\sum_{k=1}^{10}\mathrm{gtc}_{k}\log(c_{k})+(1-\mathrm{gtc}_{k})\log(1-c_{k})\]
$[gtc_1,...,gtc_{10}]= gtc $ 是对应于输入网络的label,\([c_1,...,c_{10}] = c\) 是color head的网络的输出。在标注完所有样本的color annotations 之后,生成一个COCO格式的json file作为输入,在推理阶段,我们沿用最初在DeepSORT中提出的特征库方法,通过特定长度的 \(SL^{i}\) 堆栈结构 \(C^{i}\) 存储目标的衣物颜色信息。更细节的是,对于时刻t的第i个tracklet,构建clothes color information的stack \(C^{i}(t)\) ,我们将第i个轨迹段所关联目标的衣物颜色信息c(i)追加到其历史衣物颜色信息栈中。 \[\mathcal{C}^{(i)}(t)=\mathrm{append}[\mathcal{C}^{(i)}(t-1);\mathbf{c}^{(i)}]\]
- Clothes Style:类似于clothes color的方式,将clothes style 作为另外一个分类问题,训练的时候,用DeepFashion dataset中的top-20 categories,利用相似的标注过程,在训练期间,用一个交叉熵损失:
\[\mathcal{L}_{style}(\mathbf{gts},\mathbf{s})=-\sum_{k=1}^{20}\mathrm{gts}_{k}\log(s_{k})+(1-\mathrm{gts}_{k})\log(1-s_{k})\]
$[gts_1,...,gts_{20} = gts] $ 是对应于输入网络的label,\([s_1,...,s_{20}] = s\) 是style head网络的输出。在推理的时候,类似于之前的clothes的color feature bank,以特定长度 \(SL^{i}\) 的stack \(S^{i}\) 存储clothes style information。更细节的是,对于时刻 \(t \in SL^{i}\) 的 第i个tracklet,构建一个clothes style information 的堆栈 \(S^{i}(t)\),将分配给i-th tracklet的clothes style information \(s^{(i)}\) 追加到它之前的clothes style information stack \(S^(i)(t-1)\):
\[\mathcal{S}^{(i)}(t)=\mathrm{append}[\mathcal{S}^{(i)}(t-1);\mathbf{s}^{(i)}]\]
- Direction。用MEBOW 数据集作为orientation annotation的数据源,因为它的丰富的contextual information。MEBOW数据集涵盖了不同姿态、光照条件、遮挡类型及背景等多种情境下的人体类别多样性,这使其成为开发和评估人体姿态方向及方向估计模型的理想候选数据集。另外,MEBOW数据集包括了orientation和body direction的annotations。在数据集中,human orientation \(\theta \in [0,360)\) 被划分为72个bins。subjects的images通过YOLOX的backbone,作为一个feature extractor。提取的特征随后被拼接,并经过更多残差层处理,最终通过一个全连接层和72个神经元作为输出p,位于方向预测头中。每个neuron的输出,\(p_k\) 表示body orientation \(\theta\) 在 \((5.k - 2.5, 5.k +2.5)\) 的区间之中,direction head的目标函数类似于MEBOW模型,从heatmap regression得到了启发,在key-point estimation任务中已经成功了,loss function如下:
\[\mathcal{L}_{direction}(gtd,\mathbf{p})=\sum_{k=1}^{72}(p_k-\phi(gtd,k,\sigma))\] \(\phi(gtd,k,\sigma)\) 是圆形高斯概率:
\[\phi(gtd,k,\sigma)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{1}{2\sigma^2}min(|k-gtd|,72-|k-gtd|)^2}\]
\(gtd\) 是gt direction bin。换句话说,该方程等价于回归一个以gt orientation bin为中心的Gaussian function。在推理的时候,对于第i个tracklet,考虑大小为1的directional information \(D^{i}\),在frame \(t \in SL^{i}\)。我们将分配给第i个轨迹段的对象的方向信息p(i)的最大索引值存入其方向信息栈中。
- Edge-features。原始的DeepSORT用一个简单的ReID 网络来提取每个object对应的edge features,用一个更强的appearance feature extractor,BoT作为ReID网络来得到appearance embeddings。另外,不像DeepSORT利用feature gallery,作者用Exponetial Moving Average(EMA) 用于appearance updating。虽然DeepSORT中的feature gallery方法,保留了一个object的embedding features,能够存储long-term 信息,但是对detection noise是敏感的。为了缓解这个问题,用feature updating 策略,对于第t帧的第i个tracklet,带有EMA的appearance state \(e^{i}(t)\) 如下所示:
\[\mathbf{e}^{(i)}(t)=\alpha\mathbf{e}^{(i)}(t-1)+(1-\alpha)\mathbf{f}^{(i)}(t)\]
\(f^(i)(t)\) 是当前分配给i-th的tracklet的detection的embedding,\(\alpha\) 是momentum term,设为0.8。指数移动平均(EMA)对目标外观信息采用随时间更新的软更新策略,且对检测噪声具有较强的鲁棒性。实验表明,EMA方法能够提升匹配质量并减少时间消耗。通过将appearance state \(e^(i)(t)\) 追加到frame t的i-th个tracklet的embedding stack \(\mathcal{E}^(i)\):
\[\mathcal{E}^{(i)}(t)=\mathrm{append}[\mathcal{E}^{(i)}(t-1);\mathbf{e}^{(i)}]\]
- Online Tracking Algorithm:与大多数依赖离线后处理实现良好性能的最先进跟踪算法不同。作者这里聚焦于online tracking。
- Tracking Separately:作者提出的tracker不仅适用于pedestrian tracking,也用在人行横道,不同类型的目标都是感兴趣的跟踪目标。我们根据检测目标的类别将其划分为独立的子集,并对每个子集进行单独匹配。这种设计使我们能够针对每个特定子集进行超参数优化。子集的超参数优化是一个重要的任务,因为对于Kalman 参数和匹配阈值,有很多不同的设定。否则,跟踪的性能会退化。将objects划分为subsets 阻止了不同的目标类型的ID 切换的风险。
- NSA Kalman。在在线跟踪的框架中,motion prediction是另外一个key module,为了分析motion informatin,原始的Gaussian filtering(kalman filter) 对于不完美的detections的不够robust。为了解决这个问题,用NSA Kalman 方法的idea,该方法提出了一种自适应公式来推导自适应噪声协方差 \(\hat{R}(t)\):
\[\hat{\mathbf{R}}(t)= \begin{pmatrix} 1-Conf(t) \end{pmatrix}\mathbf{R}(t)\]
\(\hat{\mathbf{R}}(t)\) 是 measurement noise covariance,通常是一个constant。\(Conf(t)\) 是时刻t的detection confidence score。这样选择的含义是 有着高score的detection有很少的noise,相应地,有很低的 \(\hat{\mathcal{R}}\),一个更低的 \(\hat{\mathcal{R}}\) 意味着 detection在state update step 有更高的weight。这个modification能够增强整体的state update procedure。
- Combined Distance:在推理的时候,除了 \(D_{motion}\) 和 \(D_{edge}\) 表示 motion distance 和 edge feature distance,作者进一步引入了 \(D_{color}, D_{style}, D_{direction}\),分别是color distance,style distance和direction distance。帧t的i-th tracklet的j-th object的 \(D_{color}(i,j), D_{style}(i,j), D_{direction}(i,j)\) 计算如下:
\[\begin{gathered} \mathbf{D}_{color}(i,j)=min\left(\mathrm{eq}(7)\left(\mathbf{c}^{(i)},\mathbf{c}^{j}\right)|\forall\mathbf{c}^{(i)}\in\mathcal{C}^{(i)}(t)\right)(17) \\ \mathbf{D}_{style}(i,j)=min\left(\mathrm{eq}(9)\left(\mathbf{s}^{(i)},\mathbf{s}^{j}\right)|\forall\mathbf{s}^{(i)}\in\mathcal{S}^{(i)}(t)\right)\quad(18) \\ \mathbf{D}_{direction}(i,j)=\left(\operatorname{\mathrm{eq}}(11)(dir^{(i)},\mathbf{p}^{j})|dir^{(i)}\longleftarrow\mathcal{D}^{(i)}(t)\right) \end{gathered}\]
Matching:对于subset matching,用匈牙利算法,这是一个通用的求解线性分配问题的算法,一个有趣的发现是尽管级联匹配算法在DeepSORT中具有重要作用,但它会随着跟踪器性能的提升而成为性能瓶颈。原因是tracker变强了,它对于confusing associations更加robust,因此,额外的先验约束会限制匹配精度。通过用匈牙利匹配解决这个我呢提,
Post Processing:在之前的部分中,执行online tracking,后处理算法可以用于进一步修正,例如Gaussian smoothing process可以被用来过滤掉outliers,平滑轨迹。另外,global linking 算法用来融合相似的轨迹,作为另外一个后处理的选项。
GSP:在匹配和更新所有的tracklets之后,在更新的tracklets的轨迹上进行GSP来调整recorded locations,插值方法普遍用来填补由missing data造成的轨迹的gaps。线性插值用于其简单,是一个直接的选择。因为其不能引入motion information,缺乏精度。作者展示了一个轻量的插值算法,用GSP来建模非线性运动。考虑smoothing equations的本质,插值受益于future observations和past observations的信息,GSP的property能够处理missing problem,对missing points用了精确的纠正的terms。对于i-th tracklet的轨迹,将GSP model 表述为如下:
\[pos^{(i)}(t)=gsp^{(i)}(t)+\epsilon\]
\(\epsilon\sim\mathcal{N}(0,\sigma^{2})\) 是高斯噪声,对于每个tracklet,它的线性插值轨迹 \(\mathbb{S}^{(i)}=\{t,pos^{(i)}(t)\}_{t\in\mathbb{T}^{(i)}}\),长度是 \(T^{i}\),GSP 旨在训练一个function \(gsp^{i}\),是一个高斯过程,能够拟合数据:
\[gsp^{(i)}=\operatorname{GP}\left(0,k(.,.)\right)\]
\(k(.,.)\) 是radial basis function kernel,考虑Gaussian process的特点,对于i-th tracklet,在new frame set 职工,对new observations进行Prediction,smoothed position \(Pos^{\\*}\) 如下:
\[\mathbf{Pos}^*=\mathbf{Cov}(\mathbb{T}^*,\mathbb{T}^{(i)})\left(\mathbf{Cov}(\mathbb{T}^{(i)},\mathbb{T}^{(i)})+\mathbf{I}\sigma^2\right)^{-1}\mathbf{Pos}^{(i)}\]
\(Conv(.,.)\) 是 convariance matrix。
- Global Linking。Global link 依赖时空信息预测两个tracklets之间的connectivity。**用GIAOTracker中的Link 算法,利用改进的ResNet50-TP来得到每个tracklet对应的3D embedding,然后用额外的spatial 和temporal distances进行assignments。GIAOTracker 将一个tracklet clip的连续的 \(N\) 帧作为输入,首先提取frame level的features,然后通过temporal modeling,输出clip features。GIAOTracker 通过额外的triplet loss,增加了part level features,使得模型关注objects的不同Parts的细节的features,对遮挡更加robust。对于temporal modeling,它们用一个Transformer encoder layer来做帧间的信息交互。之后用匈牙利算法进行tracklet assignment,i-th和j-th tracklets之间的appearance cost 是它们通过GIAOTracker得到的global encoded feature banks \(\mathcal{B}^((i))\) 和 \(\mathcal{B}^{(j)}\) 之间的最小余弦距离:
\[C(i,j)=min\{1-\langle\mathbf{b}^{(i)},\mathbf{b}^{(j)}\rangle|\forall\mathbf{b}^{(i)}\in\mathcal{B}^{(i)},\forall\mathbf{b}^{(j)}\in\mathcal{B}^{(j)}\}.\]
由于ReID的features的需求,关于DeepSORT-like范式的主要的关注是它们的执行速度。这个限制源于在detector module上单独使用一个ReID网络,导致处理速度的下降。虽然作者的结果是基于一个单独的ReID网络用于edge embedidng extraction,FeatureSORT不需要利用ReID网络来实现很好的tracking performance。这由于detector结构的修改,使得可以直接利用从detector得到features用于tracking。这样的approach使得FeatureSORT类似于joint detection-tracking算法,值得注意的是,从修改的YOLOX detector得到的features in our study可能相比于从separate networks designed for tasks such as color classification没有那样explicit。然而,这个策略在计算复杂度、处理速度和跟踪性能上取得了trade-off。
 \(Fig.1^{[1]}\)
\(Fig.1^{[1]}\)
 \(Fig.2^{[1]}\)
\(Fig.2^{[1]}\)