LLMDet
LLMDet:
Learning Strong Open-Vocabulary Object Detectors under the Supervision
of Large Language Models[1]
作者是来自中山大学、阿里等机构的Shenghao Fu等人,论文引用[1]:Fu, Shenghao et al. “LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models.” ArXiv abs/2501.18954 (2025): n. pag.
Time
- 2025.Jan
Key Words
- image-level and region-level captions
- 一句话来说:之前的开集检测器,用的都是short captions for each object,都是一些coarse descriptions,这个工作构建了一个更大的、更详细的caption 数据集,然后,利用LLM,能够作为image-level和region-level的caption,得到一个很好的开集检测器
总结
- 最近开集检测器用大量的region-level 标注的数据实现了很好的性能。在这个工作中,作者展示了,通过为每个image生成image-level的detailed captions,将开集的detector和一个LLM一起训练,能够实现性能的提升。为了实现这个目标,作者搜集了一个数据集,GroundingCap-1M,每个image都有一个关联的grounding labels和image-level的detailed caption,有了这个dataset,作者用一个标准的grounding loss和一个caption generation loss,来微调这个开集检测器,作者利用LLM来产生region-level的short captions for each region of interest 和image-level的long captions for whole image, 在LLM的监督下,得到了一个detector LLMDet,超过了baseline。
开集的object detection旨在基于用户的输入的text labels,检测任意的类别,比传统的闭集object detection是一个更加通用的detection task。GLIP首次通过region-word contrastive pre-training,统一了object detection和phrase grounding。这个formulation得益于massive grounding和image-text data,覆盖了很多的concepts,使得学习到的representations是semantic-rich,后续的工作聚焦于有效地vision-language fusion和fine-grained region-word alignment,通过scaling up预训练的数据和computation,现有的开集object detectors能够实现zero-shot的性能。 最近的工作表明了:将grounding task和其它的language tasks的统一,用language knowledge丰富了visual representations,构造了一个stronger vocabulary detector,GLIPv2在更强的grounding loss和masked language modeling loss下预训练了model,后续的CapDet和DetCLIPv3展示了,统一dense captioning和grounding 提高了开集的性能。然而,他们用了short captions for each object,例如粗糙的descriptions和层次化的class labels,都是粗粒度的,缺乏objects之间的联系,另外,long image-level captions,包含丰富的details和Image的全面的理解,比short region-level descriptions提供了更多的信息, 激励作者去探索long detailed image-level captions能够给开集detectors带来什么优势。
鉴于此,作者提出了LLMDet,用一个标准的grounding objective和caption generation objective来训练一个开集检测器,LLM是加在detector之后的,将来自detector的image features和region feature作为输入,预测image-level的long detailed captions和region-level short phrases,相比于之前的工作只对每个object产生short captions,LLMDet在四个方面超过了它们:首先,long captions为image中的每个object提供了更多的细节,long captions包含详细的object types, textures, colors, parts of the objects, object actions, precise object locations和texts, 这对构建丰富的vision-language representations是有帮助的,现有的region-level captions是一些局部简单的descriptions;其次,image-level generation将图像中的所有元素作为一个整体进行对齐,建模前景objects、背景还有多个objects之间的关系,提供了更多的信息和更全面的图像理解,超过了object-level的caption,仅关注于single regions of interest;第三,image-level captions比region-level的标注更加scalable,最近的off-the-shelf VLMs擅长image understanding,但是很难做到region-level understanding,有了合适的prompts,能够得到高质量的image-level captions;另外,完全预训练的LLM是自然的开集,用一个LLM来产生captions使得detector能够和它对齐,继承了很强的泛化能力,提升了rare class的性能。
然而,现有的grounding datasets缺乏对整个图像的详细的captions,因此,作者搜集了一个dataset,称之为GroundingCap-1M,来训练LLMDet,相比于标准的grounding dataset,GroundingCap0-1M中的每个element被formulate为一个quadruple,包含一个image, short grounding text,一些标注好的bboxes,一个长的详细的image-level的caption,一个LLM被用于理解region和image features,产生对应于每个object和image-level caption的grounding phrases,为了有效地将LLM集成到LLMDet中,保留预训练的Knowledge,首先仔细地将LLM和现有的detector进行对齐,然后将它们作为整体进行finetune。
有了新的training framework,作者展示了vision foundation model能够从LLMs的监督中受益,这个supervision不仅来自于用LLM产生的captions作为labels,也来自于co-training的梯度。
通过将改进的LLMDet和一个LLM结合,能够进一步地构建一个很强的LMM,在LLMs的监督之下进行训练,LLMDet不仅实现了更强的开集能力,也将LLMs进行了pre-aligns,因此,预训练的LLMDet能够作为一个很强的vision foundation model。
在开集目标检测中,detector在一个有效的训练集上进行训练,旨在检测用户输入的任意的类别,为了检测任意的类别,开集目标检测被表述为一个vision-language task,因此detector能够检测没有见过的class。受VLM的zero-shot能力的启发,将detectors和CLIP进行对齐或者将CLIP集成到model中作为一部分,是一个直接的解决方式,然而,CLIP使用image-level的objectives进行预训练的,CLIP中的features对于OVD任务不是完美的suitable。 或者,用大量的,来自多个resources的数据构建一个object-aware visual-language space,展示出来impressive results,另外,多任务学习,例如masked language modeling和dense captioning,能够实现更好地的vision-language alignment,提高了detector的开集能力。然而,先前的工作仅关注于产生regions of interest的short phrases,在这个工作中,作者探索了另外一个co-training的task,用LLMs产生image-level的详细的captions。
最近,VLMs让LLMs有了很强的visual perception和understanding的能力,一个常见的VLMs包含三个部分:vision foundation models来提取vision tokens,一个projector将vision features map到language space,一个LLM来理解visual 和text input,最近的工作发现,一个更好的vision encoder改善了最终的VLM的多模态的性能。但是LLM是否能提高vision encoder是很少被探索的,InterVL将CLIP-like的vision encoder进行了scale up,用一个LLM作为text encoder,在这个工作中,作者展示了detector也能够从LLM中获益,改进的detector能够提高多模态的性能。 为了训练一个更好的VLM,一个高质量的caption data是必不可少的,captions的质量是训练一个开集detector的key factor。因此,作者利用现有的高质量的caption datasets和先进的VLMs来产生高质量的数据。
作者将每个training sample formulate为一个四元组,\((I, T_g, B, T_c)\), I是image, \(T_g\) 是short grounding text,B是对应grounding text的bboxes,\(T_c\) 是整个image的详细地caption,搜集详细的captions的时候有两个core principles:1. caption应该尽可能包含更多的details,希望这个caption能够描述object types, textures等;2. caption应该只包含事实性的details,太多imaginary或者reasoning的captions会降低信息的密度。
将grounding task和其它的language tasks进行统一,丰富了vision features,扩展了vision concepts,实现了更好的vision-language alignment,先前的工作主要关注于dense captioning,language model用于产生short captions或者class names来描述single region of interest,然而,single objects的details,objects和前景、背景信息之间关系被忽略了,但是这个信息在single detailed image-level caption中是能被描述的。在这个工作中,作者站了region-level 开集目标检测器能够在LLM的监督下,受益于long detailed image-level captions。 具体地,作者用一个LLM来产生captions,基于预训练的DETR 开集检测器,因为detector和LLM是分开训练的,首先训练一个projector,将来自detector的vision features map到LLM的input space,然后将p5 feature map作为LLM的输入,LLM被用来产生full image captions,在这个过程中,仅有projector被tunable。
在pre-alignment之后,detector,projector和LLM以端到端的方式进行finetune,除了原始的grounding task,包括word-region alignment loss \(L_{align}\) 和box regression loss \(L_{box}\),作者还引入了两个tasks:image-level caption generation和region-level caption generation。
- image-level caption generation task: language model将来自detector的feature map作为输入,输出对应的long detailed captions,沿着常见的训练多模态大模型的方法,作者将LLM输出的数据以对话的形式组织起来,包括system messages, user inputs, answers。user inputs包含来自detector的vision features和prompt,answers是来自GroundingCap-1M的captions,LLM旨在基于user inputs输出answers,因为输出的answers包含various details和对image的全面的理解,这些visual cues应该被建模在visual features中,因此LLM能够最小化training loss,产生正确地captions。
然而,因为LLM将这个feature map作为input,对于LLM来说,很难将image-level captions中的entities映射回整个image中的specific region,例如,disher只是image中的一小部分,image中有很多类似dish的objects,因此,作者进一步引入了region-level caption generation task作为补充,为LLM提供了先验,用对应的word映射回region。在这个task中,作者选择了detector中positive object queries,这些queries和ground truth boxes是匹配的,用LLM来产生它们对应的grounding phrases。类似于image-level generation, LLM的输入在对话中也被格式化了,但是用了不同的prompt来分割不同类型的inputs,在single object query中的visual feature是受限的,作者在LLM中增加了一些cross-attention layer for object queries,用来从detector's feature maps中搜集必要的信息,注意到,在image-level generation中, text tokens和visual tokens不经过这些cross-attention layers,这些layers是从零开始训练的。通过输出object queries对应的phrases,LLM能偶将entities和对应的region进行匹配。
LLMDet的整个的training objective是grounding loss和generation loss的结合:
\[\mathcal{L} = \mathcal{L}_{align} + \mathcal{L}_{box} + \mathcal{L}_{lm} + \mathcal{L}_{region}\]
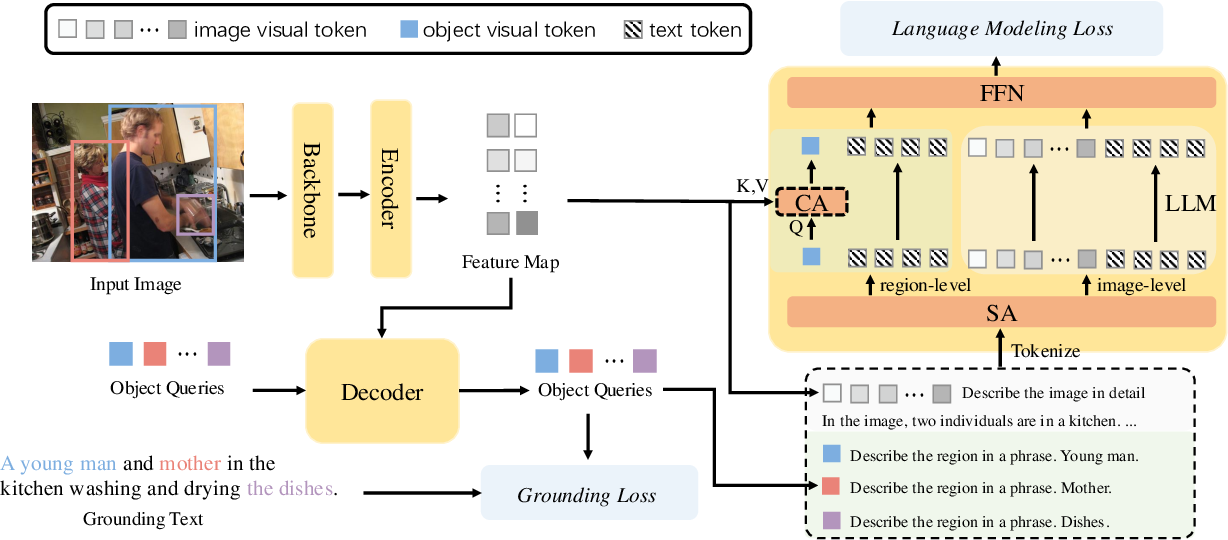 \(Fig.1^{[1]}\)
LLMDet包含一个标准的开集检测器和一个LLM,在grounding loss和language
modeling loss下进行训练,LLM将feature maps作为visual
input,用来产生imge-level captions,将single object query作为visual
input,产生region-level
captions,这通过不同的prompts进行separate,只有region-level
generation中的vision tokens通过cross-attention
modules,因为image-level和region-level generation中的vision
tokens的数量有很大的差别,作者分别将LLM forward
twice,来节省memory和computation,LLM在推理的时候被丢弃,没有额外的cost。
\(Fig.1^{[1]}\)
LLMDet包含一个标准的开集检测器和一个LLM,在grounding loss和language
modeling loss下进行训练,LLM将feature maps作为visual
input,用来产生imge-level captions,将single object query作为visual
input,产生region-level
captions,这通过不同的prompts进行separate,只有region-level
generation中的vision tokens通过cross-attention
modules,因为image-level和region-level generation中的vision
tokens的数量有很大的差别,作者分别将LLM forward
twice,来节省memory和computation,LLM在推理的时候被丢弃,没有额外的cost。